What is a Data Lake?
Data Lake is a centralized repository for all structured and unstructured data. Data Lake platforms are made available by SaaS providers like AWS S3, Azure Data Lake Storage Gen2, Google Cloud Storage, etc. As customers are looking to migrate data from Mainframes to Cloud for easy accessibility and cost-benefit, we encourage potential customers to make use of Data Lake.
Data Lake can store a huge volume of data generated by applications daily in its raw form. Enterprises can use this stored data for reporting, visualization, and advanced analytics.
How can we apply it in Mainframes?
For instance, a customer moving from Mainframe to Open-Source would convert Mainframe application code to their new technology. In such cases, the data used for transaction purposes and application execution can be migrated to a Database like AWS S3 and the other data can be migrated to Data Lake. The data in Data Lake can be used for future business growth by applying analytics.
Also, it is easy to migrate data to the Data lake, as it requires no pre-processing or schema alterations. Mphasis provides Mainframe modernization processes that are flexible enough to accommodate future changes or modifications.
Data Migration
Data Lake enables data migration from DB2 to AWS S3 or any SaaS provider. The data stored in the cloud can be queried by using any of the technologies like MongoDB Atlas Data Lake or AWS Athena, among others.
Once the data is migrated to any SaaS provider application, it is organized, analyzed, and used to create insights by extracting application features. These data-driven insights can be fed into Automation processes which will benefit the business. Further, the data generated as a result of these processes can be collected again and used to generate more insights, creating a cyclical process.
Real-time Application
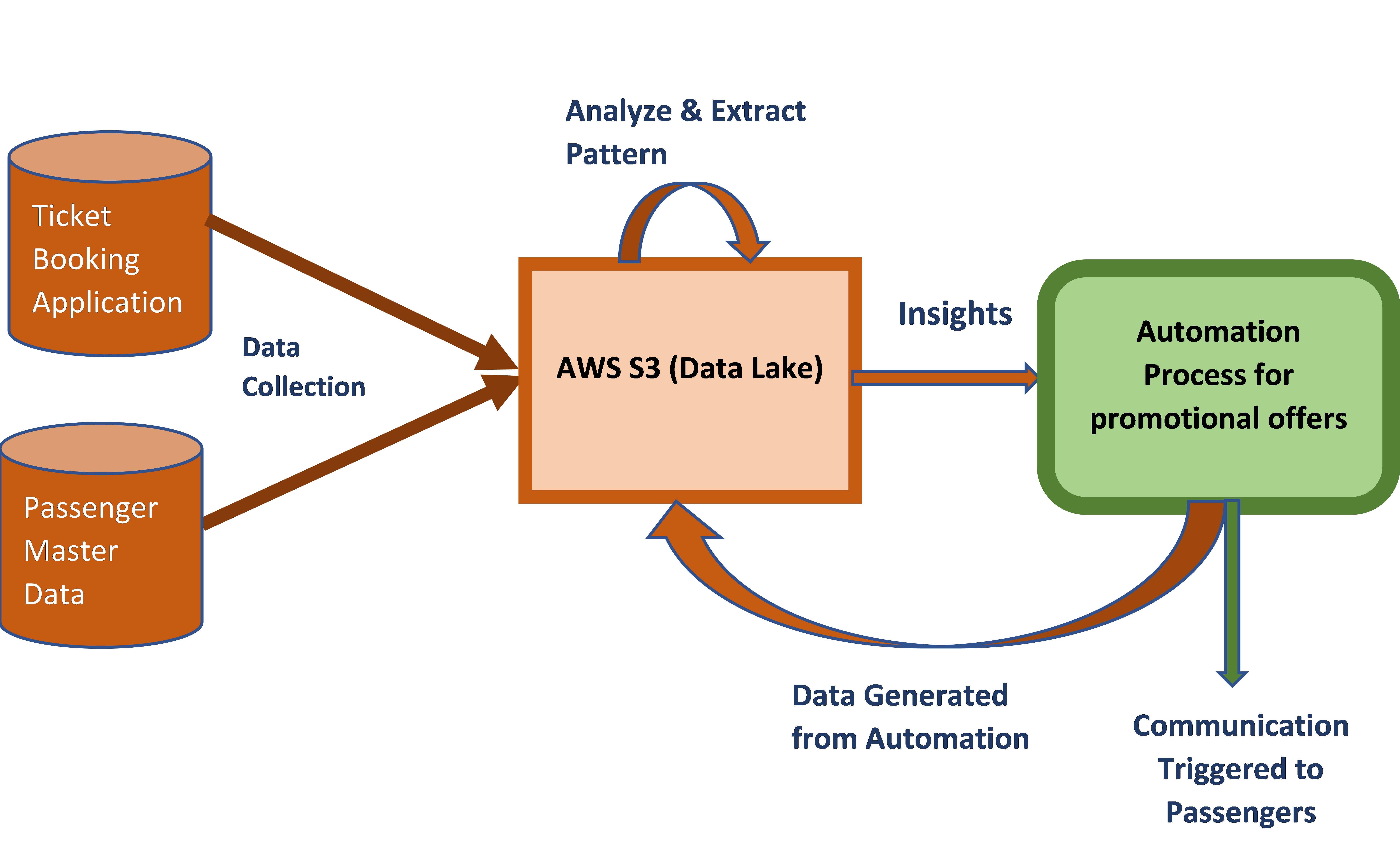
For example, if we apply Data Lake for an Airline Customer who has their core applications running on Mainframe. We can consider the Ticket Booking Application for Passenger Ticket Confirmation, which generates a huge amount of data daily, which can be collected and stored in a Data Lake (e.g., AWS S3).
We can analyze this stored data to find passengers’ booking patterns like peak demand and dull booking periods. Further, based on insights from the above analysis, we can automate the Ticket booking portal to promote and communicate offers or discounts to passengers during such periods.
Not to leave behind the data in IMS DB, we are exploring on opportunities to develop a solution to migrate the data in IMS to cloud platforms.
