Mainframe Batch Overview
With the current digital disruption, it has become imperative to have an updated infrastructure, to fulfill which, many companies and organizations have been moving some or all their mainframe workloads, applications, and databases to the cloud. With cloud services you can make mainframe applications, and the value that they provide, available as a workload whenever your organization needs it.
Mainframes are a proven platform with long-established operating procedures that make them reliable, robust environments. Software runs based on usage, measured in million instructions per second (MIPS), and extensive usage reports are available for charge backs
.
Calculating Batch Usage
The Mainframe batch usage is measured as the metric of a million instructions per second (MIPS) measureing the overall compute power of a mainframe by providing a constant value of the number of cycles per second for a given machine.
A small organization might require less than 500 MIPS, while a large organization typically uses more than 5,000 MIPS. At $1,000 per single MIPS, a large organization spends approximately $5 million annually to deploy a 5,000-MIPS infrastructure.
Migration Strategy
Batch operations in Cloud differ from the typical batch environment on mainframes. Mainframe batch jobs are typically serial in nature and depend on the IOPS provided by the mainframe backbone for performance. Cloud-based batch environments use parallel computing and high-speed networks for performance
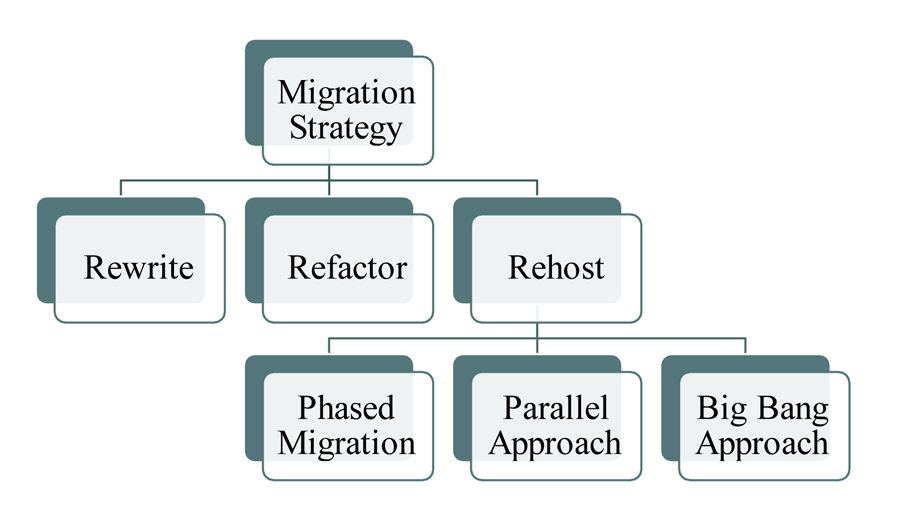
• Re-write - Re-write refers to the manual redevelopment of legacy code in a newer language, and it’s not easy because of the need to retroactively specify all software requirements. It’s difficult to certify the completeness and accuracy of the retroactive specification, making like-for-like testing nearly impossible. Furthermore, legacy mainframe applications, especially COBOL batch processes, are designed to make the most out of scarce compute resources, requiring deep technical knowledge and appropriate tooling. A manual rewrite can take many years to complete, increasing risk and reducing the overall business value proposition.
• Re-Factor - This process extracts the application model from the source code and refactors the model to the desired target architecture, forward-generating new object- and service-oriented code.
• Re-Host - Re-host uses an emulator to move, translate, and recompile legacy applications on AWS. It keeps the original COBOL code mostly intact, but it’s not a simple lift-and-shift. Rather, it’s a complex re-platforming project where the COBOL code is tailored to a permanent third-party emulator, and then adapted to many third-party utilities for output management, sorting, printing, data storage, and charge-back.
Re-Hosting Strategy
Since Mainframe applications are not natively cloud aware, re-hosting to a cloud provider like AWS(Amazon Web Services) ecosystem is an excellent way to take advantage of some of the cloud’s key features such as flexibility and scalability. Re-hosting opens possibilities to utilize many AWS services and benefits with little or no code modification. The move can also serve as a bridge to longer-term strategic digital transformation initiatives such as a rewrite or re-architecture of legacy applications to better support new business models.
Pre-requisites/Feasibility:
• Extraction of Inventory/Knowledge Base creation:
- Count and LOC of elements
- Types of elements – DB2, BMPs, Report Creation and File transfer
- Data Source and Models
- Interfaces
- Business rules, program calls & SQL Queries
- Dependencies – Critical Path jobs
- Volumetric Input and Data size
- Duplicate Analysis
Desgin
• Cloud instances: Which cloud instances would be used for Production workloads and which of them would be used for pre-production and performance workloads.
• Transaction Loads: Non-functional requirements in general, performance requirements such as high transactions per second, or quick response times are often critical for Mainframe workloads execution.
• Integration with External Systems: Since Mainframes are commonly the back-end or system of record for applications, the integrations must be preserved after migration. This includes protocols, interfaces, latency and bandwidth.

Source: https://aws.amazon.com/blogs/apn/migrating-a-mainframe-to-aws-in-5-steps/
Re-Factoring Strategy
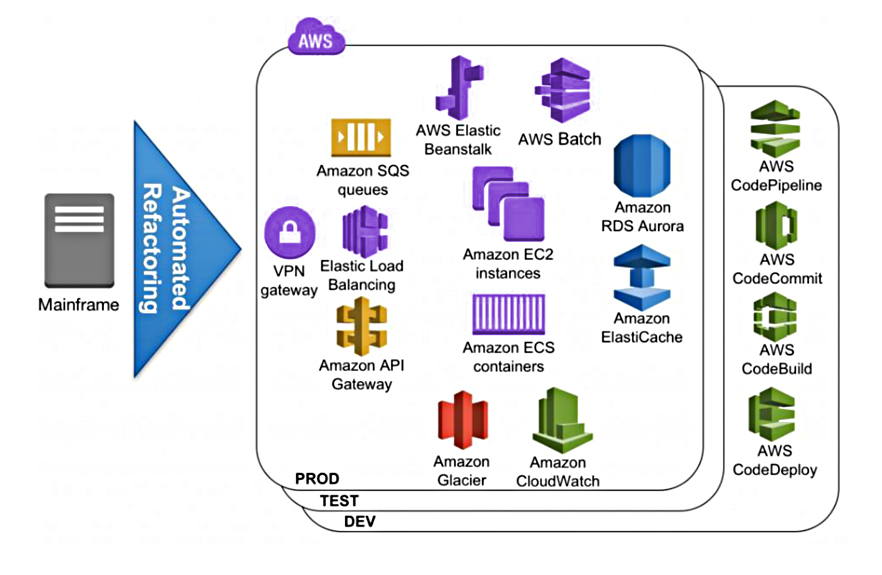
This process extracts the application model from the source code and refactors the model to the desired target architecture, forward-generating new object- and service-oriented code. The new code eliminates technical debt, taking advantage of popular application frameworks such as Angular and SpringBoot combined with AWS- managed services such as Amazon Aurora, Amazon ElastiCache, or AWS Elastic Beanstalk.
Typically, the resulting architecture of an automated refactoring effort executes on Amazon Elastic Compute Cloud (Amazon EC2) instances or Amazon EC2 Container Service (Amazon ECS) containers. Data can be hosted by Amazon Relational Database Service (Amazon RDS) and Amazon Aurora for both relational database managers (DB2 z/OS, Datacom) and modernized legacy file-based data store (VSAM, SEQ).
Elastic Beanstalk can automatically manage capacity provisioning, load balancing, and automatic scaling of compute instances. Mainframe in-memory distributed data structures can be stored in Amazon ElastiCache, and after automated refactoring the resulting micro-services are accessible directly via the Elastic Load Balancer. They can also be accessed asynchronously via Amazon SQS or as an Application Programing Interface (API) via Amazon API Gateway. The mainframe batch programs can be submitted and dispatched with AWS Batch.
References:
https://aws.amazon.com/fr/blogs/apn/blu-genius-for-mainframe-to-aws-cloud-native-transformation/
https://docs.microsoft.com/en-us/azure/architecture/cloud-adoption/infrastructure/mainframe-migration/overview
https://aws.amazon.com/blogs/apn/how-to-migrate-mainframe-batch-to-cloud-microservices-with-blu-age-and-aws/
