The most important algorithm in machine learning (ML) today is deep learning, a neural network algorithm that has breakthrough applications in natural language processing (NLP), natural language understanding (NLU), image recognition and predictive modeling. The downside to deep learning is that it requires tremendous amounts of computation to train the neural nets, so we need to use specialized hardware that can speed the huge number of matrix multiplications.
Neural net practitioners originally started using accelerating hardware in the 1980s, but generalized use began after Nvidia’s introduction of CUDA to facilitate the use of their GPUs in 2007. Nvidia’s GPU remained the deep neural net workhorse for several years, but Google’s introduction of the Tensor Processing Unit (TPU) in 2018 on GCP gives users a way to speed training while reducing costs and power consumption. This post explores the speedup obtained by comparing the performance of Google’s 3rd generation TPUs to Nvidia’s GPUs and weighs the superior performance of a TPU against its drawbacks.
Google’s TPU is not a panacea; they have so much processing power that the user has to choreograph the ingestion of data to ensure that the individual TPU cores are fully utilized. Channeling data to the TPU so that all 8 of its cores spend most of their time engaged in computation requires using sharded files (in our case TFRecord) and the tf.data API to ingest the training data, so achieving the same level of utilization is more challenging for a TPU than it is for a GPU.
Training a deep neural net demands a lot of computation, which translates into time and money. So, how does a TPU compare to a conventional GPU in terms of training time and cost? Let us look at benchmarks for the TPU (TPU type v3-8) and GPU (Nvidia P100) using Martin Gorner’s ‘Five Flowers’ Kaggle dataset. We’ll consider the training time required for a deep neural net that can classify images of five different types of flowers as determined by the batch size, which is the number of samples trained on before updating the neural network weights. The graphs below show how the TPU performed relative to the GPU; note that the GPU didn’t have sufficient memory to generate results for the larger batch sizes:

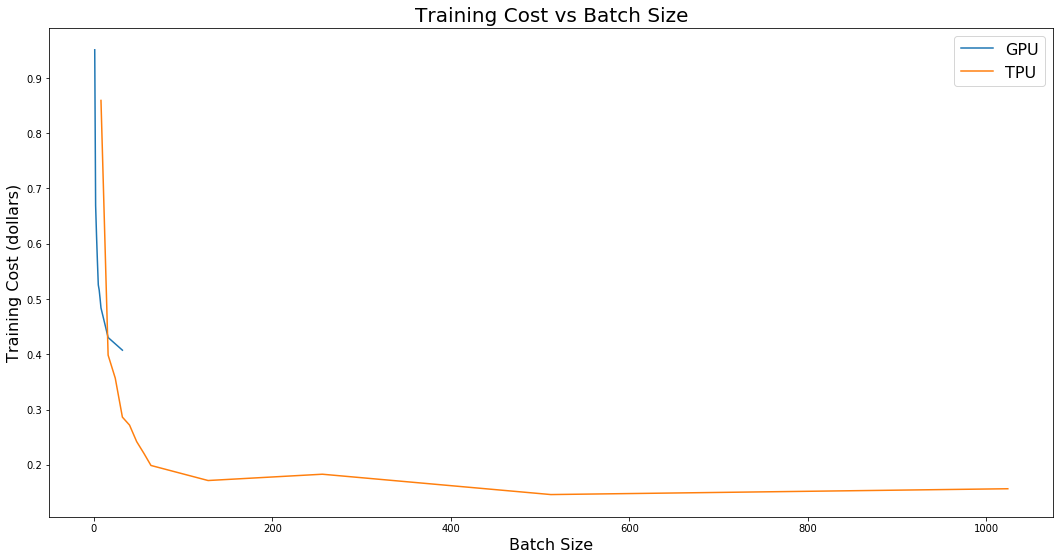
The results indicate that speedups by a factor of more than 15 are possible, but they appear to come at a cost. First, v3-8 TPU’s pricing is 5.5 times greater than for the P100, which by itself sounds alarming; however, calculating the amount of training per dollar yields a monetary savings of more than 64% since the TPU is so much faster.
Although it costs a little more to develop the code to support the efficient utilization of a TPU, the decreased training expense will usually exceed the increased programming expenditure. There are other reasons to use a TPU; for example, the 128 G of VRAM for v3-8 exceeds what Nvidia cards come with, which makes the v3-8 an easier choice for processing big models associated with NLP and NLU. Increased speeds also can lead to faster iteration through development cycles, resulting in faster and more frequent innovation, thus raising the probability of success in a competitive marketplace. Ease of use, speed of innovation and cost - all lean in favor the TPU over the GPU; cloud architects and users should give the TPU consideration in their machine learning and AI projects.
