Introduction
Serverless computing is a concept that has been in practice for last 5 years. It is popular mainly with all public cloud platforms such as Amazon Web Services, Azure, Google Cloud Platform etc.. Introduced by Amazon in the year 2014, with the launch of their service called Lambda, serverless picked up pace as it was extremely handy in certain practical business use cases around building modern applications.
This article is focused on the various aspects of serverless computing across different popular public cloud platforms such as serverless computing concepts, examples from real life, benefits, limitations and so on.
Let’s get our serverless engine started...
Overview of Serverless Computing
Popularly known as FaaS (Function-as-a-Service), serverless computing, as a concept, started as early as in 2006. The first commercially successful serverless computing services known as Lambda was launched in 2014 by Amazon Web services. Today, it is the most popular computing service in the world of public cloud platforms.
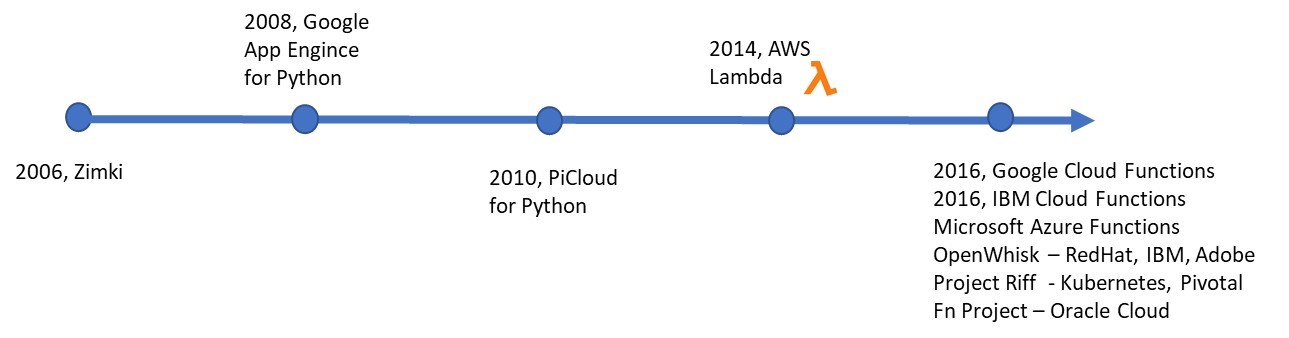
Soon after Lambda was launched, AWS competitors also launched their own serverless services and platforms.
What is serverless??
As per Techopedia.com:
Serverless computing is a type of cloud computing where the customer does not have to provision servers for the back-end code to run on, but accesses services as they are needed. Instead, the cloud provider starts and stops a container platform as a service as requests come in and the provider bills accordingly.
Also,
Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity, says Wikepedia.org
To keep it simple, Serverless -
- leverages cloud resources such as compute and storage without a need to provision them
- Is a type of computing that charges based on the use
- Uses a managed shared services infrastructure provided by the public cloud platform
However, serverless doesn’t mean running something on a cloud without any infrastructure or a hardware resource. That has not yet been possible, but who knows this could be a reality in the next couple of years.
Why Serverless?
It is really important to know why the public cloud platform vendors launched the concept of serverless computing.
Imagine a situation where:.
We have to run a specific custom-built program, API service for only few times a day on cloud. In a conventional world, I would spin up a VM instance, install all the necessary software and then deploy the code binaries. I will then set-up a scheduler on the VM to run the service/code/API as necessary. Imagine if I have this requirement to run tens or hundreds of such custom applications on my cloud platform, how expensive it is going to be!
What if I am able to leverage a shared resource provided by the cloud vendor that doesn’t demand the need for spinning up VMs? Something that can provide you the option to run your custom code written in the most popular modern languages by virtue of a trigger, and promises top class availability and resilience on the platform?
Apply the same situation onto a highly volatile microservices-based modern web application running hundreds of functions in the backend. You can imagine how many resources one can save in deploying this on a serverless architecture
Having said that, without hesitation I admit the need and awareness to qualify anything and everything that one wants to run on a serverless architecture. This is a highly debated topic in the cloud architect circle all around the globe!
Simple Serverless Examples
While I have given a couple of them above while explaining why we need serverless, let us take some other simple use cases which come handy in real life. There are a plenty of serverless resources available with each public cloud vendor,
- Triggering a nightly job that runs less than 5 minutes and finishes the task.
- Triggering an email to the concerned members, the moment a specific workflow status becomes “Completed”
- Processing an image file or a pdf document, the moment it lands up on a storage service on a cloud platform
Serverless in Popular Public Cloud Platforms
Let us now look at the serverless computing services available under each of the popular public cloud platforms
Amazon Web Services
Starting with Lambda in 2014, AWS has come a long way in serverless computing. 2017 has been a remarkable year with AWS announcing lot of serverless twins of existing services and has only kept increasing. For more details visit:
AWS also provides a serverless application repository, which is a huge pool of serverless components built on top of AWS services, available for free and can be used by anyone who is interested.
Microsoft Azure
Microsoft makes serverless available to its Azure consumers via Functions. A code repository of Azure functions is also available
Pivotal Cloud Foundry
Pivotal is working on its new serverless Pivotal Function Service. It comes with a host of pluggable features, scalability, support on Kubernetes and Istio, container-based workflows and polyglot programming.
Google Cloud Platform
Google cloud functions provide the ability to build serverless application backends, real-time data processing and to build intelligent applications. Google provides a plugin for serverless framework (www.serverless.com). The code base for the plugin is available.
IBM Cloud Functions
Based on Apache OpenWhisk, IBM Cloud Functions is a polyglot Functions-as-a-Service (FaaS) programming platform for developing lightweight code that performs scalable execution on demand. It offers an array of functionality for Back-ends, Mobility, Data, Cognitive with IBM Watson, IOT, event stream processing, conversational bots and scheduling
Serverless.com
While we looked at popular cloud computing platforms and their support for serverless computing, another framework that is worth mentioning is serverless.com. Stared as an open source project in 2015, it has now grown into a mature enterprise grade framework. Serverless.com is now supported on AWS, Azure, GCP, Kubeless, Cloudflare and Openwhisk.
Serverless Computing – How it is misconstrued
Serverless doesn’t mean running without infrastructure. The name is misleading if we consider its literal meaning. Serverless is a collection of software components that run on an underlying hardware, with a difference that the allowance doesn’t have to be paid for the infrastructure components/services when not in use, as opposed to a conventional usage of a VM on cloud. The serverless functions cannot run for longer duration and can last for only minutes. So, it will not be a fit for every practical business scenario.
Serverless is often confused with PaaS since both operate on a similar shared infrastructure model. But serverless was built as an enabler to do specific tasks, whereas a PaaS is built for tasks such as email service, database services, messaging/queueing, caching/In-memory for performance, application integration services, security services etc.
The pricing model of Serverless is different from that of PaaS. While PaaS can be persistent, serverless cannot.
Having said that, each public cloud service provider is now trying to redesign or launch their existing PaaS services to adopt serverless model.
Serverless and Containers – A Compare and Contrast view
While these are two contemporary technologies which are very much in action currently and more so in the future, it is important to understand the differences between the two. We know that serverless is all about executing functions or services on a cloud platform, container on the other hand is a hosting platform that can run a small service or an API to a large modern or legacy business application in one or more compartmentalized units.
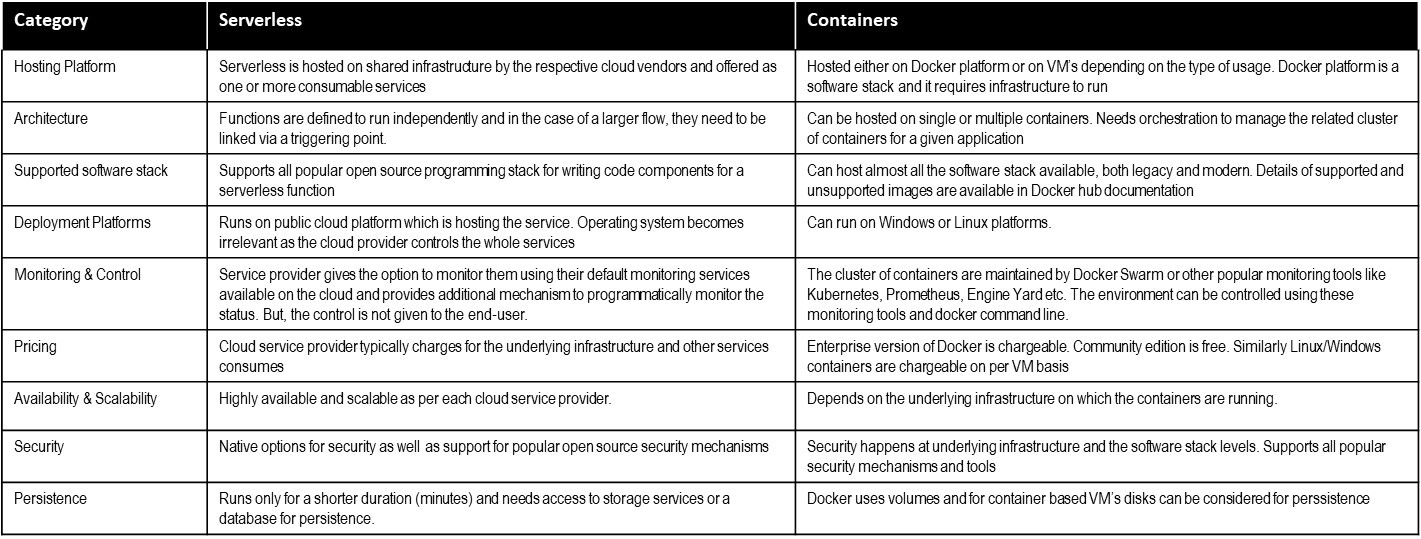
While we looked at a comparison between the two popular technologies, this big question is, “What are serverless containers?”
AWS launched Fargate, a serverless container platform during its Re-Invent event in 2017.
Microsoft made it possible with what is known as Azure Container Instances.
Google launched in its Google Next event this year, a platform called “Cloud Run”. It is “a serverless compute platform that lets you run any stateless request-driven container on a fully managed environment. In other words, with Cloud Run, you can take an app—any stateless app—containerize it, and Cloud Run will provision it, scale it up and down, all the way to zero!”
There could be more such services/platforms available. But, it is important to understand how the concepts of serverless and containers are combined in each of them and whether they really qualify for the need that you may have on hand.
Serverless Benefits, Limitations, Challenges and Areas of improvement
Every technology has its own set of benefits, limitations, challenges and scope for improvement. Given below is a summary of the same:
Benefits
- Avoids the need of managing/maintaining the underlying infrastructure as it is taken care by the cloud service provider
- Cost efficiency as there is no need to spin up dedicated infrastructure for tasks that are infrequent
- Versatility to perform and complete any task that is smaller in nature across board
- Scalability of serverless platforms offers the freedom to be elastic on need basis
- Support for writing the functions in multiple programming languages to perform the needed task
Limitations and Challenges
- Not suitable for long running tasks
- Is not persistent, need storage service or a database service if any data needs to be retained
- Applications built have the risk of vendor lock-in as it will be based on the underlying serverless platform of the cloud provider
- Monitoring may be a challenge if there are too many serverless tasks running at the same time.
- Design for any small component or large application should be built in a way that it takes care of failure scenarios and error handling. For example, if a specific serverless function crashes, how to either recover or restart the same service again. This could be complicated if there are upstream or downstream dependencies.
- Fail-fast mechanism/approach is advised for any POC/prototype to be built on a serverless architecture/model. This way we can avoid wastage of time, human resource and money.
Areas of Improvement
As technologists, we would really love to see serverless computing evolve and its limitations disappear. Some areas which needs improvement and will be helpful to the community are:
- Ability to increase the active/run duration and attain persistency
- New models/designs of underlying infrastructure (compute) that will be more relevant to serverless from longevity, performance, scalability, availability perspective
- Need for common serverless architecture/framework to avoid the risk of vendor lock-in and making them agnostic of underlying cloud platforms.
- Cross cloud portability of existing serverless services or mechanisms to fast-track portability between cloud platforms for situations like an API platform or a serverless rich web application.
- Proper tool (IDE) for development community to easily build functions and applications on serverless.
Some or most of them may eventually evolve and become a reality. But, it is at the discretion of each cloud service provider as they control it. It is also a possibility that overengineering can end up killing the very basic purpose of serverless.
Serverless as a technology is still evolving across different cloud platforms and also on the open source community. Early adoption of this technology will certainly give benefits to enterprises. Equally important is the selection of use cases to fit a serverless computing scenario.
While more and more services are getting shifted to serverless model on each cloud platform, the limitations and challenges are still prevalent. The architecture typically supports modern microservices-based functions.
As an architect or a serverless evangelist, one has to strive for building serverless functions and applications that are cloud agnostic (no vendor lock-in). This is possible through externalization/segregation of actual business functionality from cloud platform specific serverless functions or services, which needs to be standardized and published to the relevant audience to promote reusability. Such models should evolve in about 1 or 2 years from now.
References
https://aws.amazon.com/serverless/
https://aws.amazon.com/serverless/serverlessrepo/
https://azure.microsoft.com/en-in/services/functions/
https://github.com/Azure/Azure-Functions
https://pivotal.io/platform/pivotal-function-service
https://cloud.google.com/functions/
https://github.com/serverless/serverless-google-cloudfunctions
https://cloud.ibm.com/functions/
https://www.ibm.com/cloud/functions
https://serverless.com/
https://azure.microsoft.com/en-gb/services/container-instances/
https://cloud.google.com/blog/products/serverless/cloud-run-bringing-serverless-to-containers
https://markheath.net/post/serverless-containers-aci
https://searchaws.techtarget.com/tip/Compare-AWS-Lambda-to-Azure-GCP-serverless-platforms
https://techcrunch.com/2019/05/23/serverless-and-containers-two-great-technologies-that-work-great-together/
https://thenewstack.io/key-differences-in-security-management-for-serverless-vs-containers/
https://dzone.com/articles/the-drawbacks-of-serverless-architecture
https://github.com/wso2/ETAC/blob/master/outlooks/serverless_outlook.md
