One of Unix's several groundbreaking advances was abstract devices, which removed the need for a program to know or care what kind of devices it was communicating with. Older operating systems forced upon the programmer a record structure and frequently non-orthogonal data semantics and device control. Unix eliminated this complexity with the concept of a data stream: an ordered sequence of data bytes which can be read until the end of file.
Another Unix breakthrough was to automatically associate input and output to terminal keyboard and terminal display, respectively, by default — the program (and programmer) did absolutely nothing to establish input and output for a typical input-process-output program (unless it chose a different paradigm). In contrast, previous operating systems usually required some—often complex—job control language to establish connections, or the equivalent burden had to be orchestrated by the program.
Source: Standard_streams lemma on Wikipedia, October 2021
Standard streams – what a great concept it was
The origins of stdin and stdout can be traced back to Unix V5 for the PDP-11 computer series, released in 1973. In today's distributed systems designs, these core ideas are still worth considering. The notion of abstract devices maps easily to our desire for loose coupling. When we design and build a component that is to be part of a larger distributed system, we cannot (and should not, really) pre-determine which other components it will be connected to.
The automatic association of input and output to keyboard and terminal display maps to the notion of wiring; the routing of requests and notifications through a network of components. The pipes and filters pattern is a popular wiring design for maintaining independence and flexibility. Service wiring is an example of a cross-cutting concern that is best managed by a service chassis. As such, it is an example of external control applied to a service.
Enter the data plane
In earlier articles, I wrote about the observability and controllability of distributed systems, and I introduced the notion of a control plane. In contrast, the routing of requests and notifications through a network of components, and the general flow of data through that network, is the domain of the data plane.
Interoperability is defined as "a characteristic of a product or system, whose interfaces are completely understood, to work with other products or systems, at present or in the future, in either implementation or access, without any restrictions" (Wikipedia). In a distributed system, we need interoperability for components to work together in the data plane. We'll discuss service integration styles, the need for communication channels and our intention to hide much of that complexity from the component developers. As a heads-up: I'll be leaning heavily on controllability for the separation of concerns.
Synchronous or asynchronous service integrations
Much has been said and written about the differences between synchronous and asynchronous communication methods. Bernd Rückerdescribes the various communication methods using the analogy with a pizza delivery scenario. Generally speaking, service integration is neither fully synchronous nor fully asynchronous. In particular, request/reply style integrations ('queries') are often synchronous (i.e. blocking), at least from the service consumer's perspective. Event-based integrations, where the sender simply informs others of a change, are naturally asynchronous. Command-style integration, where the sender is telling the recipient to 'do its work', results in either a reply back to the sender or an event informing others of a change.
Public service endpoints
When designing for interoperability, it's important to distinguish public integration points from private, internal integration points. Public integrations adhere to a contract, potentially with many (external) parties. Breaking the contract, i.e. modifying the interface in a way that is not backwards compatible, is highly impactful and should be avoided wherever possible. Note that, in this context, 'public' includes everything that is outside application scope. Business services, intended for re-use within an organization, also expose public service endpoints.
Public service endpoints are almost always realized as an API, an Application Programming Interface, following the synchronous request/reply paradigm. REST-based integrations have become the norm, here. Long-running operations are supported using HTTP 202 and HTTP 303 response codes. Truly asynchronous public integrations are rare because the interface contract is much more complex in that case.
Intra-application service integration
For intra-application integrations in a distributed component-based architecture, asynchronous integration methods prevail. The availability of Kafka as an enabling technology certainly has given rise to the popularity of event-based or streaming integration models, though Kafka is certainly not a prerequisite for successful interoperability.
Intra-application integrations still come with a contract, but the counterparties to the contract are well known and generally under the same program of project management umbrella. Hence, breaking the contract is less impactful, compared to the public integration interface contract. This is not to say that the open/closed principle does not apply – the interface should still be well-defined and stable.
Channels – standard streams for distributed systems
Interoperability in a distributed system is a shared concern both for the system architect and for all component designers. Hence, it is advantageous to address it as an aspect and deal with it as part of the service chassis.
The service logic, which is the reason why a component is developed in the first place, can deal with interoperability using the modern-day equivalent of stdin and stdout. These are queues or, more generally, channels. A component consumes tasks or requests coming in on an input channel and produces responses or events on one or more output channels. The wiring of those channels is not the concern of the service logic designer and should be delegated to the chassis. Think of this as dependency injection on steroids, with the service chassis as mediator.
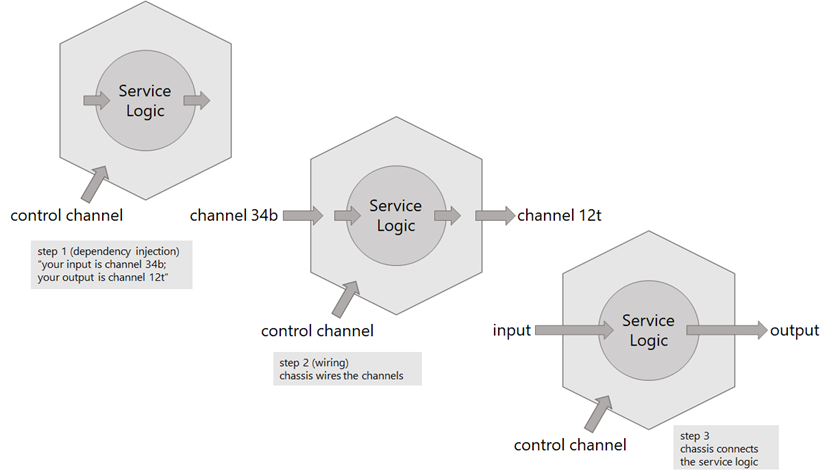
Role of the chassis in component wiring
Channel payload design
Using channels as standard streams solves one problem of interoperability but leaves another design aspect unsolved: what is the general shape of commands, responses, and notifications? For a distributed system, this is still a key aspect of the overall design, and one that needs to be taken care of early in the process. Standardization and industry best practices are still emerging, cloudevents and asyncapi are trending in this space.
The channels provide part of the technical integration solution, but the semantic integration requires work. In between those there is also data serialization, compression, encryption, authentication, and authorization which can & should all be taken care of by the service chassis.
Channel wiring
Because of loose coupling, and with the guidance from early Unix experts, we understand that a component shall be informed of its incoming and outbound integration flows only at runtime. The component itself, i.e. its service chassis, doesn't know about its connections up until the moment it is brought to life as a process (regardless of whether the component is running on bare metal, on a virtual machine or in a container). This is not uncommon, in fact significant experience in this space comes from the concept of service registries like zookeeper and etcd.
OK, we have pushed the responsibility down, now what? In a distributed system, which component will know how to create a topology of component integrations that makes the application work as one whole? And how would such information be passed to the participating components? The answer to these questions lies in controllability – as noted earlier, we need a new feature, i.e. a deployed compo¬nent, that is responsible for issuing control instructions to the application's services. I'll come back to this is a follow-on blog.
A channel is a channel is a channel
Channels are nice, abstract concepts that an architect can live with. The reality is different. Let us look at some of the desirable features of a channel, in the context of distributed systems.
Queue or topic?
In many cases, an architecture calls for reliable delivery of payload ('messages') from a sender to a recipient. In some way ordered, preferably with some level of reliability. A first-in first-out or FIFO mechanism is what is needed. Traditionally, a Message Queue. Or a pipe, in Unix terms. But maybe, just maybe, there is a need to inspect the flow of messages. A wiretap on a queue will help, more generally a Topic or a publish-subscribe channel provides the required functionality, as long as it provides durable subscriptions.
In some messaging solutions, a channel is either a queue or a topic, and one must make a choice when the channel is created. ActiveMQ and RabbitMQ are popular choices for a message broker, having both topics and queues as separate features. Other solutions (Kafka, for example) don't even support the concept of a queue, and everything is a topic. As an aside, Kafka is a different kind of messaging solution altogether, but we won't elaborate on that here. Finally there are messaging solutions that only let you publish to a topic and read from a queue. Elegant, simple, and straightforward. NSQ is a distributed messaging platform using topics and queues, though confusingly NSQ refers to queues as channels.
Resilient or scalable?
Both resilience and scalability are desirable properties of a messaging infrastructure. Central message brokers, deployed on a cluster of servers for scalability, require an elaborate distribution of channels for balancing the load across the cluster nodes. For resilience, message brokers rely on high availability configurations, leading to HA-configured messaging clusters. Distributed messaging solutions are better adapted to scale-out, as each broker ultimately deals with the message traffic of one single channel, only.
For resilience and durable message delivery, message brokers must be capable of buffering to persistent storage. This is where the analogy with Unix pipes breaks down; pipes are an in-memory construct, not an on-disk construct.
Channel placement
Using a centralized message broker, software architects have no say over the placement of their channels in the network – all channels 'live' on the message broker. When you're lucky, you're allowed to incorporate a message broker in your own solution. But, like a DBMS, it's more likely that a message broker is centrally managed by IT or by your cloud service provider. You can only hope that your application will be deployed on the same subnet as where the broker lives, to avoid additional network latencies.
Distributed message brokers are designed to be co-located with the services that need them. With a distributed message broker, solution architects have the freedom to place a channel:
- close to the publisher (especially useful when there is only one publisher for a topic, i.e. single fan-out),
- close to a recipient (useful in large fan-in situations),
- elsewhere (for reasons of resource utilization and system manageability).
In general, such decisions need not be delayed until the moment of deployment; rather, they are part of the deployment specification, which describes the desired topology of a distributed system.
Observable channels
I wrote about observability earlier. I believe channels should be considered first-class citizens of a distributed system. Hence, each channel should be observable, and indeed controllable. Especially during application integration testing, purging a channel is a control feature that is indispensable. The ability to measure queue dwell times and queue depth contributes significantly to observing the overall health of a distributed application.
Most message brokers, both centralized and distributed, provide some level of observability and controllability. That's a good start, but what is important to ensure is that such brokers are also externally observable and controllable, via an API or a message flow.
Public service endpoints for a distributed system
We discussed channels as the primary abstraction for intra-application service integration. Still, we may have a need to expose service endpoints for external use. As we saw earlier, such service endpoints are typically realized as synchronous request/reply operations. So, how do we integrate a synchronous request/reply pattern in an otherwise asynchronous, event-driven component design?
One approach is to extend the design of a component to include an API, either in the chassis or in the service logic core. Such an API could replace or complement the normal task input channel. There are some concerns with this design, in particular:
- All issues around identity and access control now come straight to the component
- All auditing and logging requirements are now part of the component's responsibilities
- Load balancing across multiple deployed instances of a component requires consensus around the use of port numbers etc.
- DDOS attacks are touching on the core services directly
- The blocking behavior of an API call directly impacts the runtime behavior of the service itself
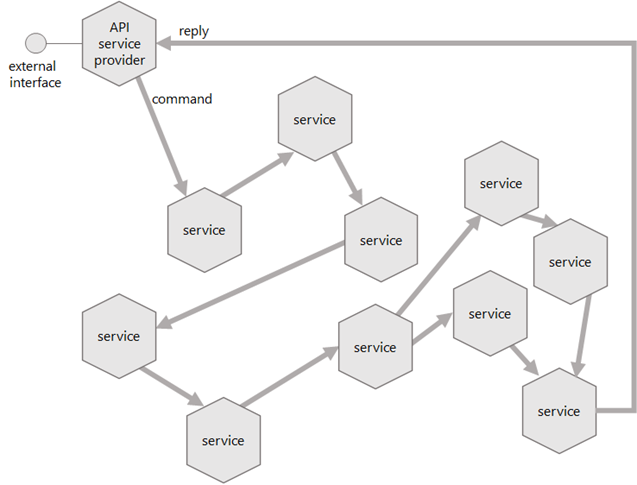
API service at the edge of an asynchronous distributed system; arrows represent channels
For these reasons, it is advisable to avoid such an aggregated responsibility and instead introduce 'edge' components that act as blocking API service providers on one side and as non-blocking request/reply messaging component on the other side. This is known as the half-synch/half-async pattern (Schmidt).
