The executive branch is the part of government that enforces law and has responsibility for the governance of a state. Source: Wikipedia, lemma Executive (government)
An earlier article discussed the interoperability aspects of a distributed system, introducing the notion of a topology of component integrations, managing that topology, and making a distributed system operate as one whole. The article described the need for a component responsible for issuing control instructions to the application's services. This component is the ‘supervisor’ of the application. It has authority over the workers, i.e., the service components of the application. In doing so, the supervisor has responsibility for the governance of the application.
This article will elaborate more on the role and responsibilities of the supervisor in a distributed component-based system.
Role & Responsibilities of a Supervisor

The concept of a software application does not apply to a distributed system. It is not a single installable object, it is not managed as a single process at runtime, and it is neither built nor maintained as one whole. So, when viewed from the inside (i.e. the design, build and maintain perspectives), a distributed system is truly distributed. But when viewed from the outside (the use perspective), the distributed system acts as an application or a product, with an application owner (or a product owner), a feature backlog, business users, etc. For the outsiders, the system has an identity as one whole, e.g., "Card Checking is down".
The supervisor of a distributed system acts as a representative of that system, in other words, it is the application. To put it more mildly, the supervisor is the only component that has at least some notion of the concept of an application. This comes with a significant number of responsibilities. Let's review these now.
Awareness
The supervisor ensures that there is some level of oversight and awareness over the total set of components that comprise an application.
As Nicolai Josuttis said, back in 2007: The danger with distributed systems is that any one component can break the whole system. It is the responsibility of the supervisor to avoid this scenario.
Control plane setup
Supervisor is the job title of a lower-level management position primarily based on authority over workers or the workplace. A supervisor is first and foremost an overseer whose main responsibility is to ensure that a group of subordinates gets out the assigned amount of production when they are supposed to do it and within acceptable levels of quality, costs, and safety.
In a distributed event-driven system, the supervisor controls both the components (i.e. the services) of a distributed system and the communication channels between those components. The supervisor communicates with the components of the distributed system using a control channel; components that experience exceptions report back to the supervisor using an exception channel. Combined, this forms a control loop. It is not the only control loop in a distributed system, but it is the most direct one.
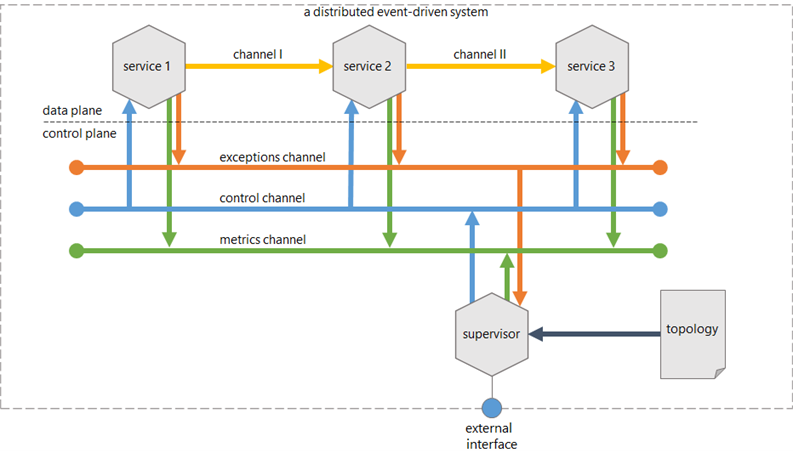 Figure 1 Supervisor operating in the control plane
Figure 1 Supervisor operating in the control plane
The supervisor exposes an external interface which makes the supervisor controllable. This way, the supervisor accepts external control instructions on behalf of the application. Note that the supervisor is both controllable and controlling.
Finally, the supervisor itself is observable, and it shares its observations on the metrics channel. One can argue that the supervisor also observes, as it receives exceptions from the service components.
Interpretation of the topology
A distributed system is not simply a group of components that operate in splendid isolation. Instead, events are passed from one component to the next to trigger work in that subsequent component (supposedly, this is the essence of an event-driven architecture). In Figure 1 above, the arrows flowing from service 1 to service 2 and from service 2 to service 3 represent this event passing. How events flow from one component to another, for all components combined, defines the topology of the application.
Earlier, it was stated that the supervisor is the application. Now, it is time to refine that and state that the topology description defines the application, and the supervisor interprets that definition to become aware of the application. This is an advanced example of configurability or late binding: the supervisor is a completely generic piece of logic that derives all its purpose from a topology description document.
Initially, the supervisor is not associated with any of the components mentioned in the topology. The application is not quite ready to run yet, because the topology has not been realized. In fact, it is not even clear where these components are supposed to reside. The decision of component placement is best delegated to a utility that is not part of the application itself.
Assembling the application
As the supervisor is not aware whether the participating components are deployed or not, it is best to reverse the dependency and let the supervisor await the announcement of the participating components. The application is registered with a service registry, and contributing components subsequently discover the application.
With registration in place, a component can discover the control interface of the supervisor and announce its presence to that interface. The response to an announcement is either an acknowledgement of success or failure ("go away, I did not expect you here").
Runtime State & Topology
As more and more components announce themselves to the supervisor, the runtime topology of the application starts to fall in place. It is the responsibility of the supervisor to maintain an up-to-date view on the state of the application; which components are deployed and where, which channels are created, and where are these channels located? Is the application complete and runnable? Is it running? Which components have scaled out to multiple instances? That is the sort of state the supervisor maintains.
Control over components
In its supervisory role, controlling the application components is a primary responsibility of the supervisor. Some areas of control include:
- Managing the lifecycle state of components.
Components of a distributed system cannot operate in any meaningful way outside of the application context. It is only when a component is fully integrated in the application fabric (including channel wiring, monitoring and control channel setup, and exception channel setup) that the component is potentially runnable. - Threading, or rather multi-threading of components.
Components of a distributed system cannot operate in any meaningful way outside of the application context. It is only when a component is fully integrated in the application fabric (including channel wiring, monitoring and control channel setup, and exception channel setup) that the component is potentially runnable. - Controlling the observability of components.
This idea was discussed earlier in "Controllability is queen". As part of a component's observability design, its control interface accepts instructions to manage the flow of metrics and adjust settings such as the moving average window. It is the responsibility of the supervisor to issue such control instructions. - Responding to exceptions raised by components.
In a distributed system, it is advisable to delegate technical exception handling to the supervisor: inform the supervisor of the problem and let the supervisor take corrective measures. - Requesting components to report on the API services they expose.
Despite the fact that distributed systems are predominantly event-driven, there are natural cases where a request/response model is better suited. Private APIs need to be discoverable only to other components of the same application. Hence, the supervisor is the ideal component to take on the role of a local service registry. - Requesting components to re-evaluate their configuration.
Individual components of an application can be asked to re-evaluate their configuration. This control instruction comes from the supervisor, possibly as a result of an external trigger.
Channel lifecycle management
The supervisor is in control of the creation of communication channels. Depending on the choice of messaging infrastructure, channels are created either centrally or distributed. While a distributed messaging infrastructure is preferrable, it comes at the cost of deploying message brokers alongside each component of the application. A centralized message broker is simpler to deploy and simpler to control, though it is potentially a throughput bottleneck and a bandwidth hog.
Using a centralized broker, the supervisor can create all channels once the topology description is interpreted. In contrast, a supervisor using a distributed message broker will need to interpret the topology, decide on optimal placement of the channels, and then await the announcement of the services before it can create the channels.
Non-functional Requirements
Thus far, various responsibilities of the supervisor were identified, these are the things the supervisor is expected to do. Over and above these capabilities, a supervisor is expected to have certain behavioral characteristics driven by non-functional requirements.
Observability
Because the supervisor holds a certain amount of state about the application, it should be expected that changes in state are observable from the outside. In addition, detailed application information, such as its deployed topology, should be made available through an API.
Controllability
The supervisor is the entry point for external control, as detailed in the section "Control plane setup" above.
Resilience of the Supervisor
As stated earlier, the supervisor maintains the application state. When a supervisor terminates unexpectedly, the application operates in an unmanaged fashion. A newly started instance of the supervisor should be able to take on the supervisory role with the help of the application state. Hence, the supervisor itself need not be resilient, but its state should be persisted at all times to ensure recovery after supervisor failure is possible, without stopping the application.
Scalability & performance of the Supervisor
The supervisor operates in the control plane of a distributed system, not in the data plane. There are no high-volume message flows through the supervisor, only small snippets of control. Hence, the supervisor does not need significant scalability in its design, only resilience.
Application-level Security
In this article, there is no in-depth discussion of security. Not because it is irrelevant, but because it is complex. It needs a separate article. Here is the gist of that discussion.
There are two schools of thought on distributed system security. One is to say that all parts of a distributed system live behind the firewall hence they are all trusted. Any interaction with the outside world is via an API, and an API gateway handles trust. The other school of thought says that there is no implicit trust anywhere. That is the zero-trust doctrine, which is the trending doctrine of this season.
Closing the Loop
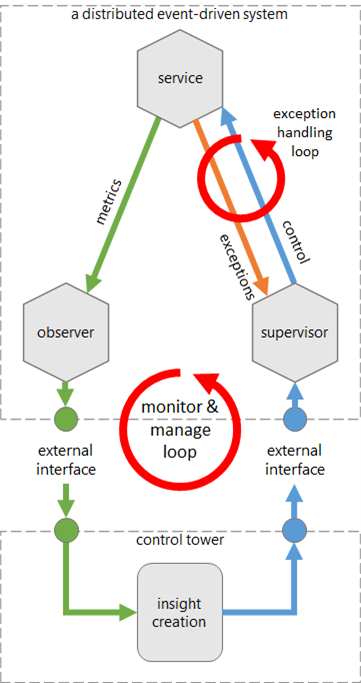
Using the exception channel and the control channel, the supervisor closes a tight control loop. This loop is completely contained within the application boundary.
A second control loop exists, based on monitoring and managing the application from the outside. This loop is based on the notion of observability and controllability at the application level, and the loop is closed using an external system.
Mphasis positions its Smart Control Tower as that system. However, the observability of the application, and the role of an observer, has not been discussed thus far; an upcoming article will close that gap.
Conclusions
In this paper, the role of a supervisor in a distributed system is elaborated. As a reader, you may conclude that the supervisor is too complex, has too many responsibilities. This has a reason.
Because there will be many different components, even for a single application, and there is only one design and implementation of a supervisor needed across all distributed systems, it is best to avoid complexity in the (many) components at the cost of increased complexity in the (singular) supervisor.
